2025 LLM 法律實測:哪個國際大型語言模型最懂台灣法律?Claude 3.7 勇奪第一,OpenAI 慘輸?
很多人會好奇:「哪一款國際大型語言模型LLM在台灣法律領域表現最好?」為了解答這個問題,我們實際測試了多家主流模型,與最近期發布的模型,以下是整理與觀察結果。測試顯示,Anthropic Claude 3.7以驚人的72.0%正確率領先群雄,而Google Gemini Flash以輕量級模型之姿也達到68.7%的優異成績,OpenAI的模型則表現令人失望。
關鍵字
法律AI模型;Claude 3.7;Gemini Flash;LLM比較;台灣法律應用
各大模型表現一覽
我們針對主要國際大型語言模型進行了台灣法律題目測試,結果顯示出明顯的差異:
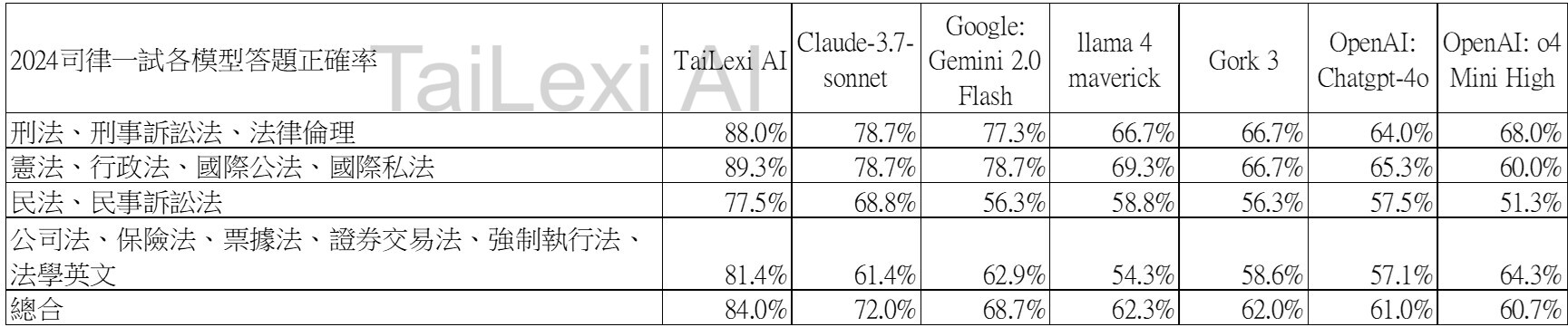
表格:2024年司律一試各大語言模型答題正確率比較
Claude 3.7:繁體中文法律的意外霸主
本次測試中最讓人驚艷的是 Anthropic Claude 3.7 達到了72.0%的正確率,遠超其他國際模型。這一結果令人感到意外,因為Claude系列模型以英文為主要訓練語言,在歐美法律界已有良好口碑,但沒想到在台灣法考的繁體中文環境中也能保持領先地位。
根據我們的分析,Claude 3.7在處理複雜法律推理時展現出了優異的能力,特別是在需要精確理解繁體中文法律術語與概念的情境下。這可能得益於其訓練數據中包含了大量高品質的多語言法律文本,以及其強大的跨語言推理能力。
Gemini Flash:輕量級的黑馬
Google Gemini Flash 以小參數版本模型的身份,卻達到了68.7%的高分,這一成績超越了許多參數量更大的模型,確實令人刮目相看。這顯示出Google在模型優化方面的技術實力,能夠在較小的計算資源下仍保持高水準的表現。
Gemini Flash在法律術語辨識和法條解釋方面表現突出,這對於需要即時回應的法律諮詢場景特別有價值。其較小的模型尺寸意味著更低的延遲和運行成本,為實務應用提供了更多可能性。
OpenAI模型:表現令人失望
我們原本計劃測試OpenAI的o3模型,但由於需要申請專屬API,流程繁複因此未能納入本次測試。轉而使用GPT-4 Mini High(正確率60.7%)進行測試,結果發現其表現甚至低於GPT-4o(正確率61.0%),反映出OpenAI的行銷與實際效能之間存在一定落差。
值得注意的是,雖然在法律專業領域表現不盡理想,但OpenAI模型在圖像生成等方面仍具有優勢,其能夠生成吉力卜風格圖像的功能讓它在消費者市場保持了高人氣。
其他模型表現
Grok 3 作為xAI的旗艦大參數模型,正確率僅約62%,結果略顯失望。這可能與其訓練數據中缺乏足夠的中文法律文本有關。
LLaMA 4系列中,Behemoth巨參數模型尚未公開,因此無法納入測試。而LLaMA 4 Maverick(正確率:62.3%)在處理繁體中文法律題目時,出現了「以英文邏輯思考並作答」的現象,反映出其訓練資料仍以歐美英文為主。
專業法律模型的優勢
我們也將自家RAG法律AI模型TaiLexi AI(正確率84%)納入比較。作為專為台灣法律條文與判決資料設計的模型,TaiLexi在處理本地法律問題時展現出明顯優勢。專業化的法律模型在理解本土法規體系、判例引用和法律推理方面,往往能提供更符合本土法律文化的解答。
這一現象並非台灣獨有。在全球範圍內,專業領域的垂直模型正在挑戰通用大模型的地位,特別是在法律、醫療、金融等專業性極強的領域。TaiLexi AI的表現證明,針對特定應用場景優化的中小模型,在實用性上可以媲美甚至超越國際大廠的通用模型。
結論與展望
本次測試結果顯示,在台灣法律應用領域,Anthropic Claude 3.7和Google Gemini Flash表現最為出色。這反映出AI技術發展的新趨勢——模型的專業性和優化程度可能比純粹的參數規模更為重要。
未來的LLM發展可能會更加注重行業垂直應用和區域文化適應,而非單純追求參數量的增加。我們也期待看到更多針對繁體中文環境優化的模型出現,為台灣的法律科技發展提供更多可能性。
TaiLexi AI團隊將持續追蹤國際模型的發展動態,同時進一步優化自身模型在台灣法律應用場景的表現,為法律專業人士和一般民眾提供更智能、更精準的法律AI服務。
參考資料
- TaiLexi AI內部研究資料,2025年5月